

Note
•
•
Sample Dataset
Region | Temp. (F) | Rainfall (mm) | Humidity (%) | Apples (ton) | Orange (ton) |
Kanto | 73 | 67 | 43 | 56 | 70 |
Johto | 91 | 88 | 64 | 81 | 101 |
Hoenn | 87 | 134 | 58 | 119 | 133 |
Sinnoh | 102 | 43 | 37 | 22 | 37 |
Unova | 69 | 96 | 70 | 103 | 119 |
•
yield_apple = (w11 * temp) + (w12 * rainfall) + (w13 * humidity) + b1
•
yield_orange = (w21 * temp) + (w22 * rainfall) + (w23 * humidity) + b2
•
Visual Representation:
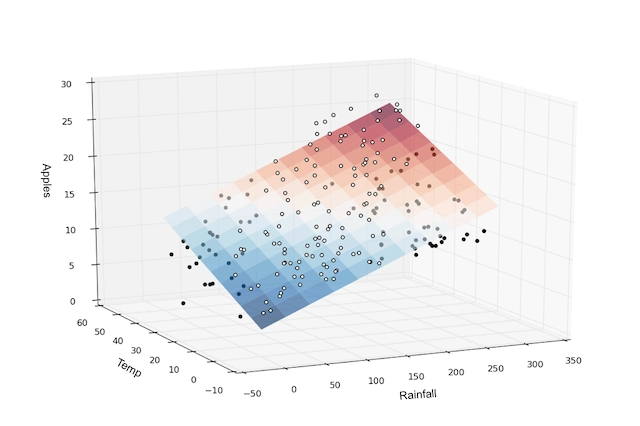
Training Data
# Input (temp, rainfall, humidity)
inputs = np.array([[73, 67, 43],
[91, 88, 64],
[87, 134, 58],
[102, 43, 37],
[69, 96, 70]], dtype='float32')
# Targets (apples, oranges)
targets = np.array([[56, 70],
[81, 101],
[119, 133],
[22, 37],
[103, 119]], dtype='float32')
# Convert inputs and target to tensors
inputs = torch.from_numpy(inputs)
targets = torch.from_numpy(targets)
Python
복사
Weights and Biases
# Create random Weigths and Biases
w = torch.randn(2, 3, requires_grad=True)
b = torch.randn(2, requires_grad=True)
Python
복사
weight is 2x3 because it follows (Num of outputs x Num of inputs)
•
Visual Representation:

Model
# Create Model
def model(x):
return x @ w.t() + b #(1)
# Generate predictions
preds = model(inputs)
Python
복사
@ represents matrix multiplication in PyTorch and the .t method returns the transpose of a tensor
Loss Function
# MSE loss (Mean Square Error)
def mse(target, prediction):
diff = target - prediction
return torch.sum(diff * diff) / diff.numel() #(1)
# Compute loss
loss = mse(preds, targets)
Python
복사
#(1) torch.sum returns the sum of all elements in a tensor and the .numel method returns the number of elements in a tensor
Compute Gradients
# Compute gradients
loss.backward()
Python
복사
Adjust Weights and Biases to Reduce the Loss
# Resetting gradients
w.grad.zero_()
b.grad.zero_()
# Adjust weights & reset gradients
with torch.no_grad(): #(1)
w -= w.grad * 1e-5
b -= b.grad * 1e-5
w.grad.zero_() #(2)
b.grad.zero_() #(2)
Python
복사
#(1) Use torch.no_grad() to indicate to PyTorch that we shouldn’t track, calculate, or modify gradients while updating the weights and biases
#(2) Have to perform .zero_() when adjusting gradients as every time you call .backward, PyTorch keeps adding values into .grad
•
Visual Representation:
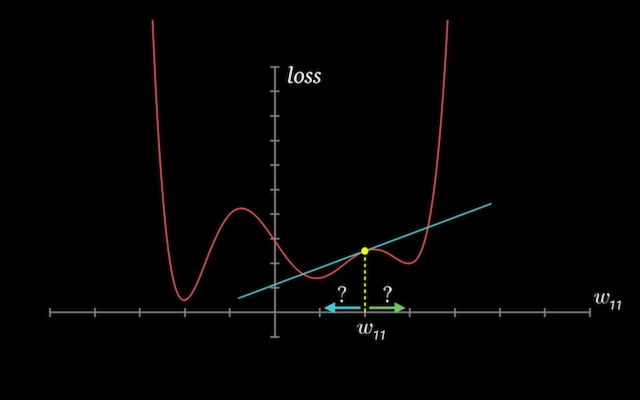
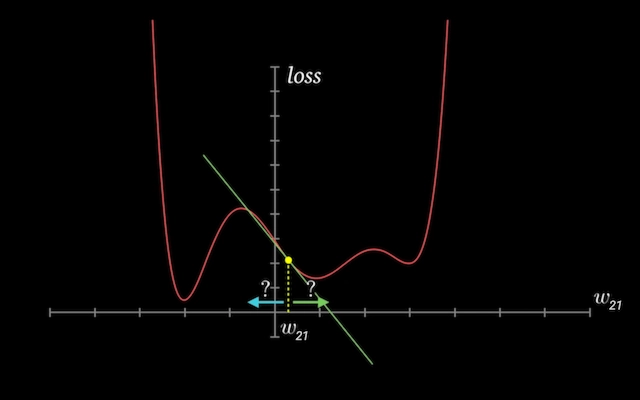
Train for Multiple Epochs
# Train for 100 epochs
for epoch in range(1000):
preds = model(inputs)
loss = mse(preds, targets)
loss.backward()
with torch.no_grad():
w -= w.grad * 1e-5
b -= b.grad * 1e-5
w.grad_zero_()
b.grad_zero_()
Python
복사
Calculate Loss
# Calculate loss
preds = model(inputs)
loss = mse(preds, targets)
print(loss)
Python
복사
